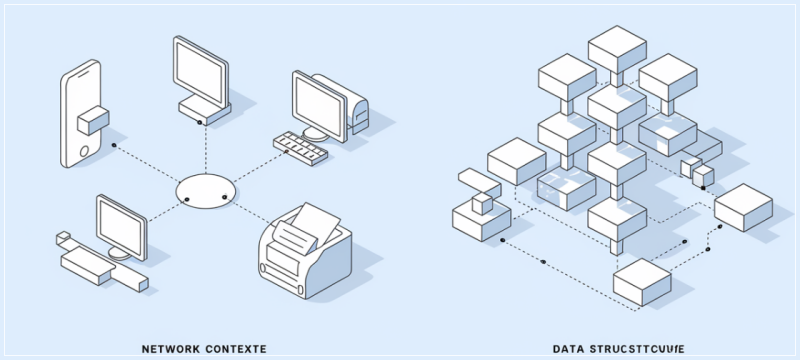
효율적인 네트워크 관리의 혁신, Intent-Based Networking 네트워크의 새로운 패러다임, Intent-Based Networking 현대의 네트워크 환경은 점점 더 복잡해지고 있으며, 이를 효율적으로 관리하기 위한 기술이 끊임없이 발전하고 있습니다. 그 중에서도 가장 주목받고 ...
TensorFlow의 매력과 활용법 TensorFlow 소개 TensorFlow는 구글이 개발한 오픈소스 머신러닝 프레임워크로, 2015년에 처음 공개되었습니다. 딥러닝과 인공지능 연구를 위한 강력한 도구로 자리 잡았으며, 다양한 플랫폼에서 머신러닝 모델을 구축하고 배포할 수 있도록 ...
Docker를 활용한 효율적인 애플리케이션 배포 Docker란 무엇인가? Docker는 컨테이너 기반 가상화 기술을 통해 애플리케이션 배포를 자동화하는 오픈 소스 엔진입니다. 전통적인 가상 머신과는 달리, Docker는 동일한 운영체제를 공유하면서도 애플리케이션을 격리된 환경에서 ...
Wi-Fi 보안의 발전: TKIP에서 WPA3로 Wi-Fi 보안의 초기 시대: WEP의 한계 Wi-Fi 네트워크의 보안은 처음부터 중요한 이슈였습니다. 초기 표준인 WEP(Wired Equivalent Privacy)는 무선 네트워크를 보호하는 데 사용되었으나, 곧 그 한계가 ...
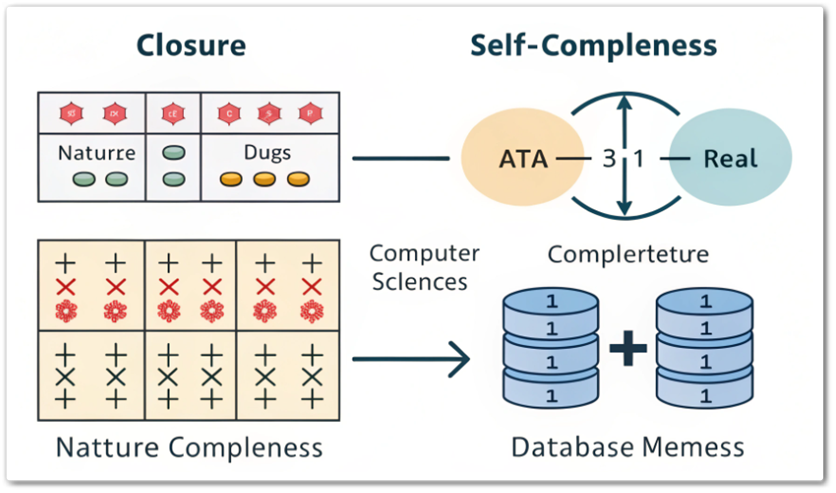
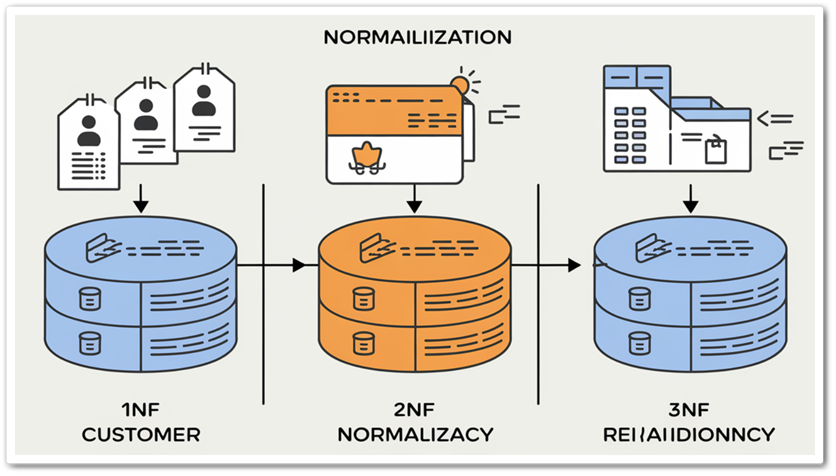
반정규화(De-Normalization) 언제 사용될까요? 정규화가 진행될수록 조인(Join) 연산이 많아지면서 성능이 저하될 수 있습니다. 이때 이런 문제를 해결하기 위해 “반정규화(Denormalization)”가 사용됩니다. 이번 글에서 구체적으로 살펴보죠. 반정규화란? 반정규화는 정규화된 데이터베이스에서 성능을 향상시키기 위해 ...
병행 제어(Concurrency Control), 데이터베이스 시스템에서 여러 트랜잭션이 동시에 실행될 때 발생할 수 있는 문제를 방지하기 위해 사용되는 메커니즘입니다. 병행 실행은 시스템의 자원 활용도를 극대화하고 성능을 향상시키는 데 유용하지만, 동시에 데이터 ...
데이터베이스에서 인덱스(INDEX)는 데이터를 효율적으로 검색하고 정렬하기 위한 구조입니다. 대규모 데이터베이스에서 데이터를 빠르게 조회하려면 인덱스가 필수적입니다. 인덱스는 책의 목차처럼 특정 데이터를 빠르게 찾을 수 있는 역할을 합니다. 인덱스의 기본 개념 데이터베이스에서 ...
시스템 카탈로그, 데이터베이스 관리 시스템(DBMS)의 핵심 구성 요소로, 데이터베이스와 관련된 메타데이터를 저장하고 관리하는 역할을 합니다. 시스템 카탈로그는 사용자 데이터뿐만 아니라, 데이터베이스의 구조와 상태에 대한 정보를 포함하고 있어 데이터베이스의 원활한 운영과 ...
절차형 SQL, 데이터베이스 관리 시스템(DBMS) 내에서 절차적 프로그래밍 언어의 기능을 제공하여 복잡한 작업을 수행할 수 있도록 돕는 확장 SQL입니다. 표준 SQL이 선언적(declarative)인 반면, 절차형 SQL은 프로그래밍 언어와 유사한 제어 구조와 ...
Debian 운영체제, 1993년 Ian Murdock에 의해 시작된 오픈소스 운영체제로, 안정성과 보안성이 뛰어나며 자유 소프트웨어 철학을 철저히 준수하는 배포판입니다. 다양한 플랫폼에서 실행 가능하며, 서버, 데스크톱, 임베디드 시스템 등 다양한 용도로 사용됩니다. ...
CentOS 운영체제, Red Hat Enterprise Linux(RHEL) 기반의 무료 오픈소스 운영체제로, 기업 환경에서 높은 안정성과 보안성을 제공합니다. RHEL과의 높은 호환성을 유지하면서도 비용 부담 없이 사용할 수 있어 서버 운영에 널리 활용됩니다. ...
Ubuntu Server, Canonical에서 개발한 오픈소스 운영체제로, 서버 환경에서 뛰어난 성능과 안정성을 제공합니다. 클라우드, 컨테이너, 웹 서버, 데이터베이스 서버 등 다양한 용도로 활용되며, 쉬운 관리와 광범위한 커뮤니티 지원이 강점입니다. Ubuntu Server의 ...
Linux 운영체제 , Linus Torvalds가 1991년에 개발한 오픈소스 운영체제로, 다양한 하드웨어 및 시스템에서 실행할 수 있도록 설계되었습니다. 서버, 데스크톱, 임베디드 시스템, 슈퍼컴퓨터 등 폭넓은 환경에서 사용되며, GNU 프로젝트와의 결합으로 자유 ...
UNIX Solaris, Sun Microsystems(현재 Oracle)이 개발한 System V 기반의 상용 UNIX 운영체제로, 대규모 엔터프라이즈 환경에서 높은 안정성과 성능을 제공하는 운영체제입니다. 특히 ZFS 파일 시스템, DTrace, Zones 등의 혁신적인 기능으로 유명합니다. ...
AIX(Advanced Interactive eXecutive), IBM이 개발한 UNIX 운영체제로, 고성능과 안정성을 제공하는 System V 기반의 상용 운영체제입니다. 주로 대기업 및 미션 크리티컬한 환경에서 사용됩니다. AIX의 특징 System V 기반의 안정적인 UNIX 환경 ...
HP-UX, Hewlett-Packard(HP)가 개발한 UNIX 운영체제로, 강력한 보안과 안정성을 갖춘 System V 기반의 상용 운영체제입니다. 주로 대기업 환경에서 미션 크리티컬한 애플리케이션을 실행하는 데 사용됩니다. HP-UX의 특징 System V 기반의 안정적인 UNIX ...
NetBSD, 이식성이 뛰어난 오픈소스 운영체제로, 다양한 하드웨어 아키텍처에서 동작하는 것이 특징입니다. “Of course it runs NetBSD!”라는 모토 아래, 임베디드 시스템부터 서버, 워크스테이션까지 폭넓은 플랫폼을 지원합니다. NetBSD의 특징 뛰어난 이식성 NetBSD는 ...
OpenBSD, 보안성과 안정성을 최우선으로 설계된 오픈소스 운영체제로, BSD(Berkeley Software Distribution) 계열의 UNIX 시스템 중 하나입니다. 강력한 보안 정책과 철저한 코드 감사를 통해 높은 신뢰성을 보장하며, 방화벽, 서버, 데스크톱 등 다양한 ...
FreeBSD, 안정성과 보안성이 뛰어난 오픈소스 운영체제로, BSD(Berkeley Software Distribution) 계열의 UNIX 시스템 중 하나입니다. 서버, 데스크톱, 임베디드 시스템 등 다양한 환경에서 사용되며, 강력한 네트워크 기능과 성능 최적화로 유명합니다. FreeBSD의 특징 ...
BSD(Berkeley Software Distribution), 1970년대 후반 미국 캘리포니아 대학교 버클리 캠퍼스에서 개발된 UNIX 기반 운영체제의 변형입니다. 원래 AT&T의 UNIX를 개선한 형태로 시작되었으며, 이후 독립적인 운영체제로 발전하였습니다. 현재도 다양한 BSD 계열 운영체제가 ...
UNIX 운영 체제, 1969년 벨 연구소(Bell Labs)의 켄 톰슨(Ken Thompson)과 데니스 리치(Dennis Ritchie) 등이 개발한 운영체제(OS)이다. 다중 사용자(Multi-user) 및 다중 작업(Multi-tasking)을 지원하는 강력한 시스템으로, 현재 다양한 변형 버전이 존재하며 서버, ...
다중행 서브쿼리(Multi-Row Subquery), 여러 개의 결과 행을 반환하는 서브쿼리로, 일반적으로 WHERE 절이나 HAVING 절에서 사용됩니다. 다중행 서브쿼리는 데이터 비교, 필터링, 그리고 분석 작업에서 강력한 도구로 활용됩니다. 다중행 서브쿼리의 특징 다중행 서브쿼리는 ...
CRUD 분석, 시스템 설계와 데이터 관리를 체계적으로 이해하고 설계하기 위해 사용되는 중요한 기법입니다. CRUD는 Create(생성), Read(읽기), Update(갱신), Delete(삭제)의 약자로, 데이터가 시스템 내에서 어떻게 처리되고 관리되는지를 분석하는 데 초점을 맞춥니다. CRUD 분석이란? ...
스토리지(Storage), 데이터의 저장, 관리, 공유를 위한 핵심 요소입니다. 데이터의 양이 기하급수적으로 증가함에 따라 다양한 스토리지 방식이 발전해 왔으며, 대표적인 방식으로 DAS(Direct Attached Storage), NAS(Network Attached Storage), SAN(Storage Area Network)이 있습니다. ...
파티셔닝(Partitioning), 데이터베이스 및 빅데이터 시스템에서 이러한 문제를 해결하는 강력한 기법으로, 데이터를 여러 조각으로 나누어 관리하는 방식을 말합니다. 이번 글에서는 파티셔닝의 개념, 종류, 활용 사례, 그리고 구현 시 고려할 점을 살펴보겠습니다. ...
클러스터링, 데이터 내의 비슷한 특성을 가진 객체들을 그룹으로 묶는 비지도 학습(unsupervised learning) 방법으로, 데이터가 미리 레이블링되지 않은 상태에서도 유의미한 정보를 추출할 수 있게 해줍니다. 이번 글에서는 클러스터링의 개념, 활용 사례, ...
윈도우 함수와 OLAP (Online Analytical Processing) 정확히 알고 계신가요? 데이터 분석을 이야기할 때, “윈도우 함수”와 “OLAP”는 종종 같은 문맥에서 언급되지만 사실 서로 다른 개념입니다. 그러나 윈도우 함수는 OLAP 작업을 SQL에서 ...
관계 해석(Relational Calculus), 관계형 데이터베이스에서 데이터를 조회하는 방법 중 하나로, 사용자가 원하는 결과를 논리적 조건으로 기술하여 이를 만족하는 데이터(튜플)를 검색하는 접근 방식입니다. 관계 해석은 SQL의 이론적 기초 중 하나로, 데이터에 대한 ...
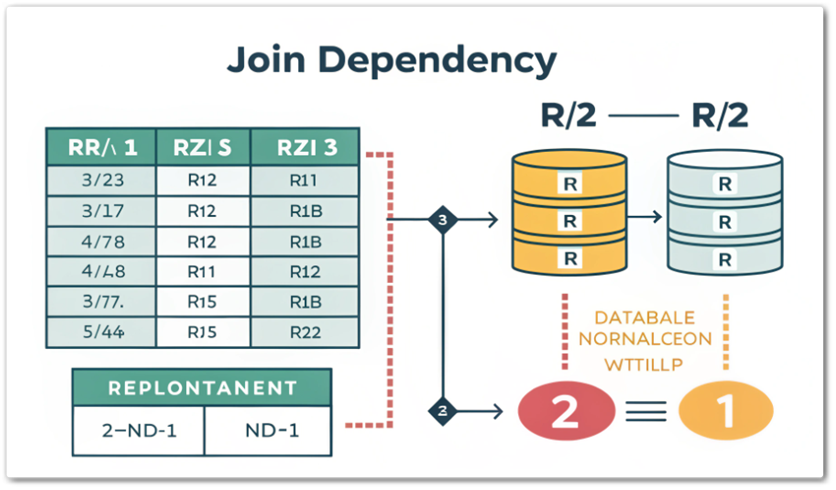
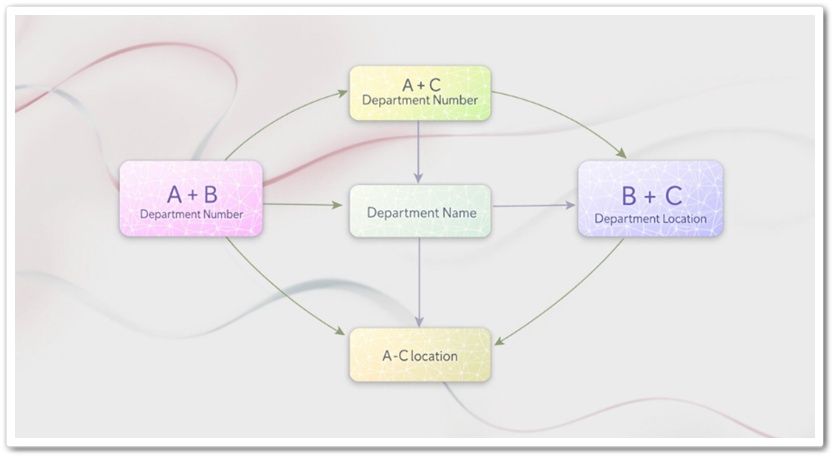
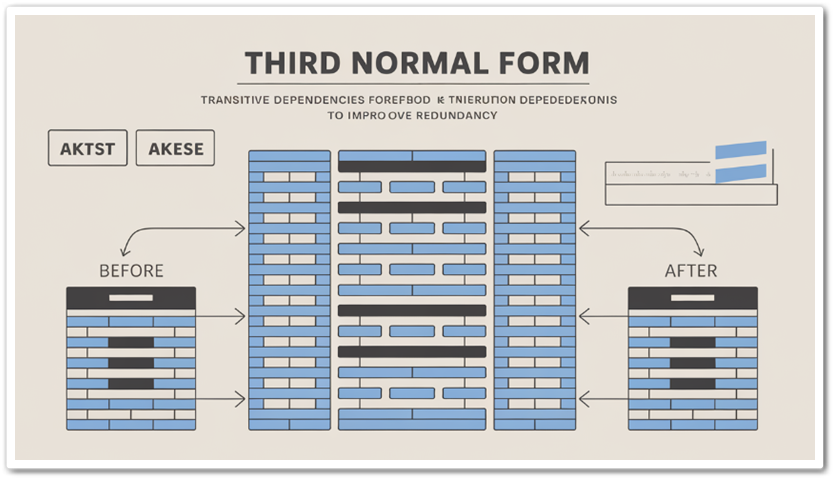
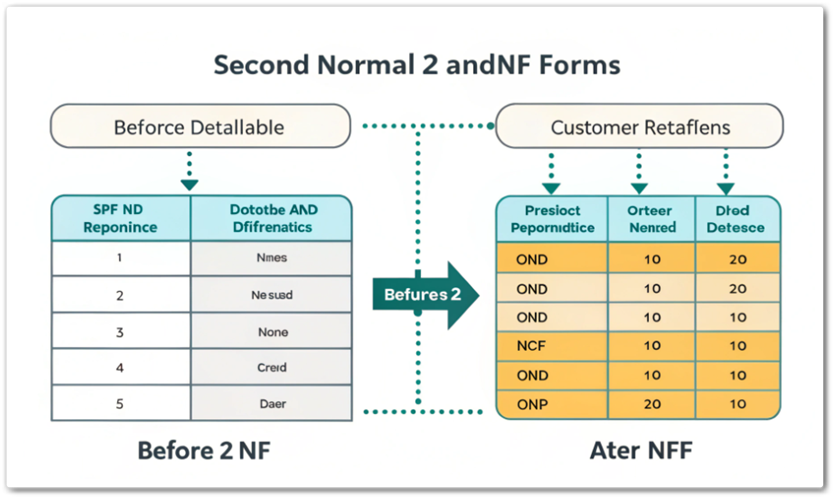
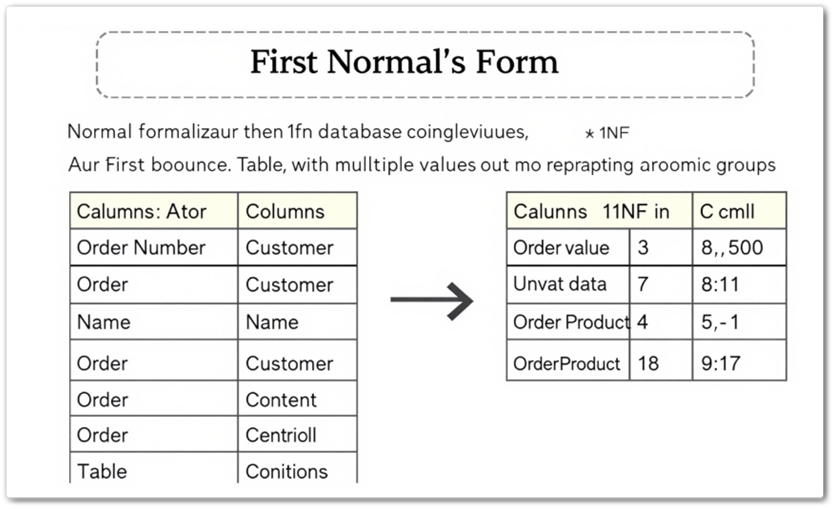
함수 종속(Functional Dependency), 데이터베이스 설계에서 관계(Relation)의 속성들 간의 의존 관계를 설명하는 개념입니다. 이는 데이터베이스 정규화 과정에서 매우 중요한 역할을 하며, 데이터 중복을 줄이고 데이터 무결성을 유지하는 데 기여합니다. 정의 함수 ...
Peter-Chen 표기법, 데이터베이스 설계 및 데이터 모델링에서 사용되는 표기법 중 하나로, 1976년 Peter Chen 박사가 고안한 개념적 데이터 모델링 방법론입니다. 이 표기법은 관계형 데이터베이스 설계의 기초가 되는 ERD(Entity-Relationship Diagram)를 작성하는 ...
데이터 모델링 표시요소와 구성요소 차이 확실히 알고 계신가요? 데이터 모델 표시요소(Data Model Display Elements)는 데이터를 시각적으로 이해하기 쉽게 표현하기 위해 사용되는 다양한 시각적 기호와 그래픽 요소를 의미합니다. 이 글에서는 표시요소와 ...
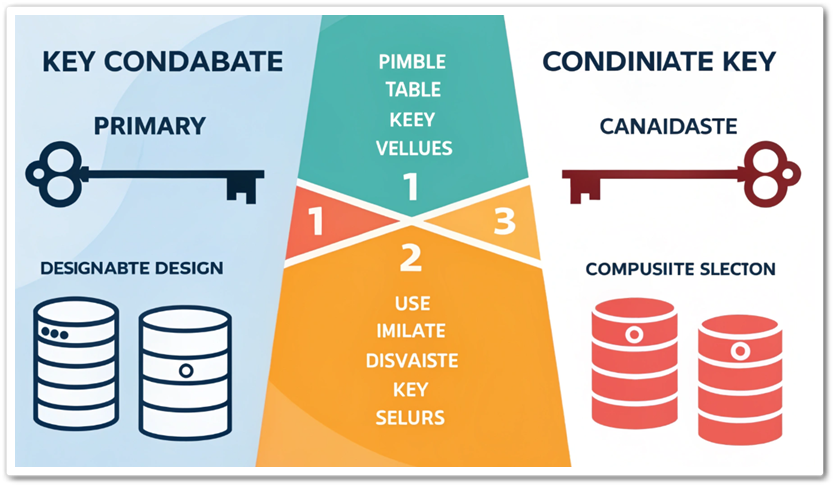
데이터베이스 설계에서 데이터를 고유하게 식별하는 “키(Key)”의 개념은 매우 중요합니다. 이 글에서는 슈퍼키(Super Key) 정의와 특징, 그리고 후보키(Candidate Key)와의 차이점을 중심으로 슈퍼키를 쉽게 이해할 수 있도록 설명하겠습니다. 슈퍼키(Super Key)란? 슈퍼키는 데이터베이스 ...
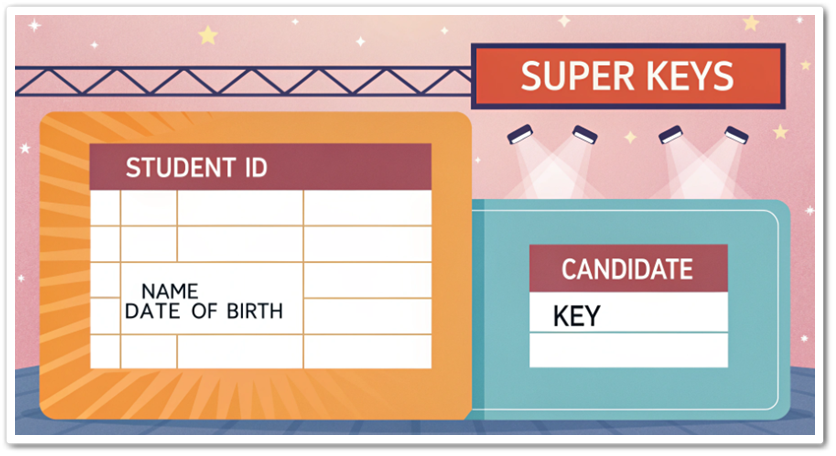
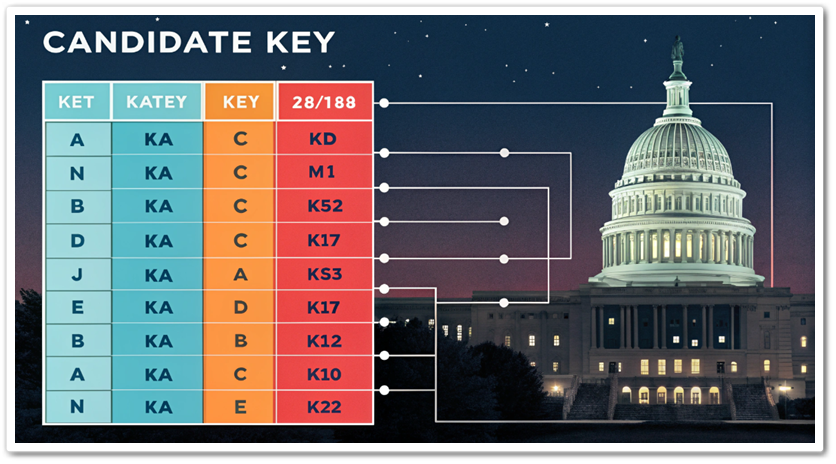
데이터베이스를 설계하거나 다루다 보면 “후보키(Candidate Key)”라는 용어를 자주 접하게 됩니다. 이 글에서는 데이터베이스 초보자도 쉽게 이해할 수 있도록 후보키에 대해 자세히 설명해보겠습니다. 후보키란? 후보키는 데이터베이스 테이블에서 각 행(Row)을 고유하게 식별할 ...
RDBMS(Relational Database Management System), 데이터를 저장, 관리, 검색하기 위한 소프트웨어입니다. 데이터를 관계형 모델에 기반하여 저장하며, 이 모델은 데이터를 테이블 형태로 표현합니다. 각 테이블은 행(Row)과 열(Column)로 구성되며, 열은 데이터의 속성을, 행은 ...
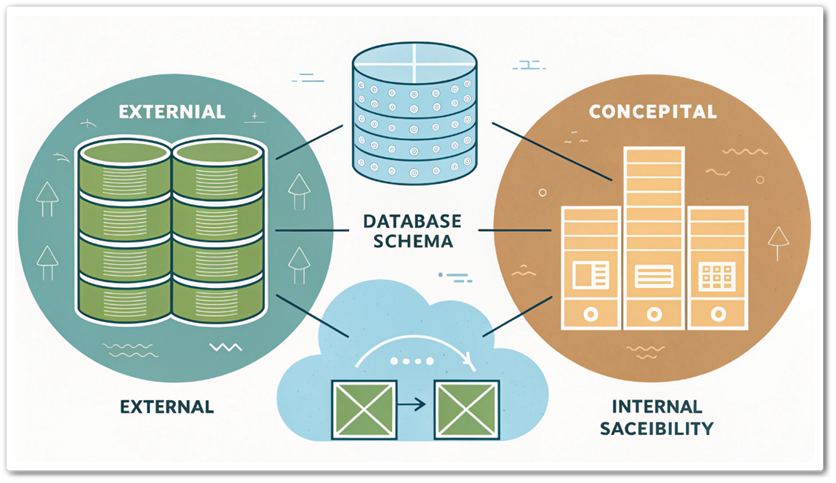
스키마(Schema), 데이터베이스의 설계도를 의미합니다. 쉽게 말해, 데이터베이스가 어떤 구조로 만들어져 있고, 데이터를 어떻게 저장하고 연결할지를 정의한 것입니다. 스키마는 데이터베이스를 설계할 때 가장 기본적이고 중요한 역할을 합니다. 스키마를 쉽게 이해하기 스키마를 ...
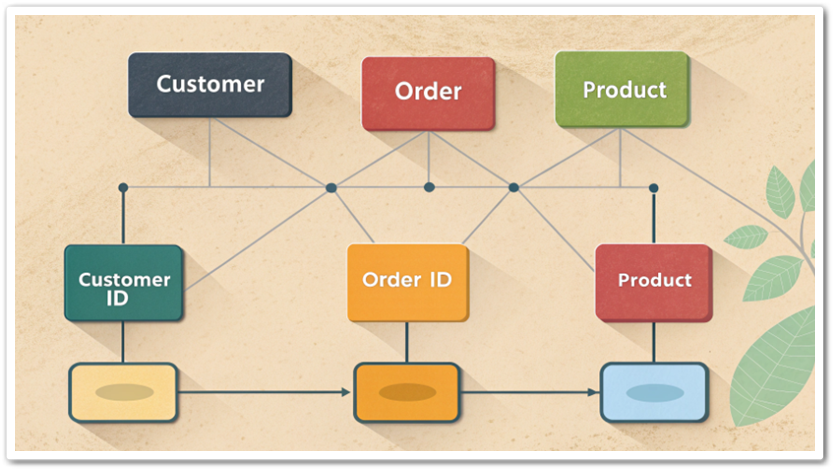
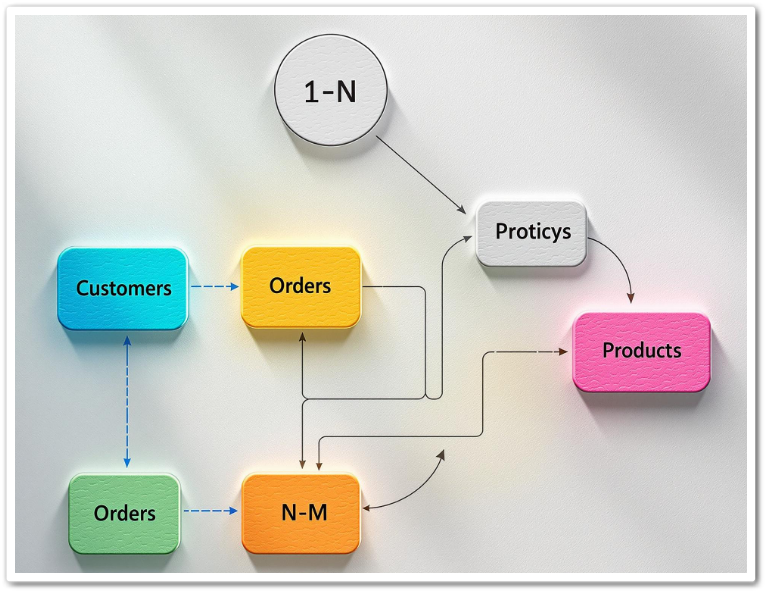
ER 다이어그램(Entity-Relationship Diagram), 데이터베이스 설계에서 데이터를 시각적으로 표현하는 강력한 도구입니다. 데이터 구조를 직관적으로 이해하고, 설계의 명확성을 높이며, 팀 간의 커뮤니케이션을 원활하게 하는 데 사용됩니다. 이 글에서는 ER 다이어그램의 정의, 구성 ...
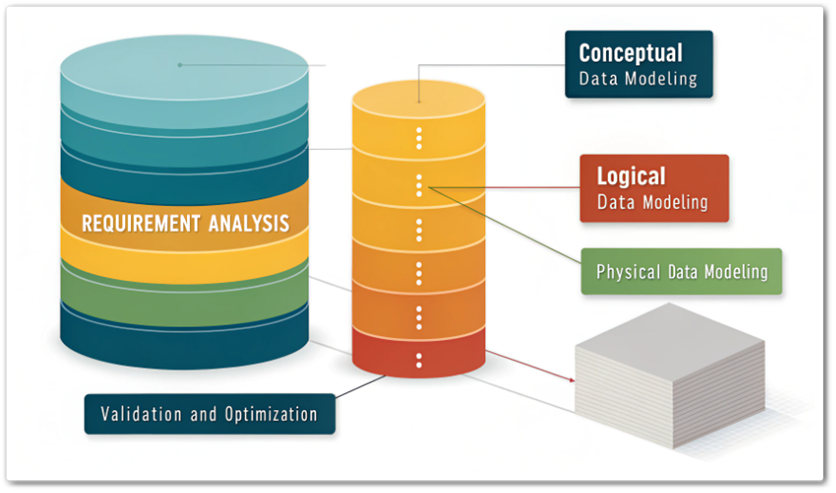
논리 데이터 모델링, 개념 데이터 모델링에서 정의된 주요 엔터티(Entity)와 관계(Relationship)를 더욱 구체화하고 정교하게 설계하는 단계입니다. 이 글에서는 논리 데이터 모델링의 정의, 특징, 중요성, 그리고 설계 방법을 중심으로 알아보겠습니다. 논리 데이터 ...
클라우드 플랫폼별 vCPU 차이점 궁금하시죠? vCPU는 호스팅에서 가장 중요한 역할을 한다고 해도 과언이 아닙니다. 이번 글에서는 플랫폼별 vCPU 차이를 자세히 설명해드리겠습니다. 읽어보시고 알맞은 플랫폼 선택하시길 기원합니다. vCPU의 개념 vCPU는 실제 ...
NUMA(Non-Uniform Memory Access) 구조, 다중 프로세서 시스템에서 메모리 접근의 효율성을 높이기 위한 기술입니다. 기존의 SMP(Symmetric Multi-Processing) 구조와 달리 프로세서가 물리적으로 가까운 메모리 영역에 더 빠르게 접근할 수 있습니다. NUMA의 기본 ...
노드(Node), 정보를 담고 있는 하나의 단위로, 네트워크나 자료구조에서 사용됩니다. 조금 이해하기 어려우신가요? 이번 글에서는 확실히 이해하실 수 있도록 아주 자세히 설명해드리겠습니다. 노드(Node)란? 노드는 네트워크와 자료구조에서 정보를 담고 있는 하나의 점 ...