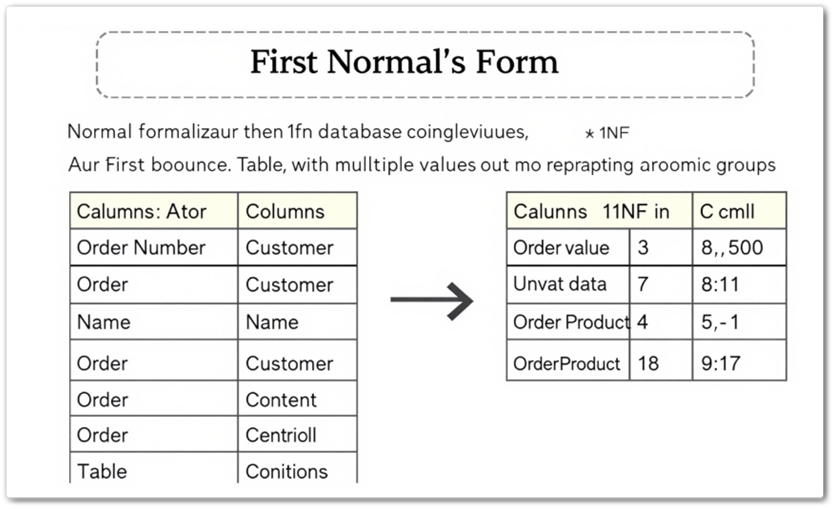
제1정규형(1NF), 데이터 테이블에서 중복과 비원자적 데이터를 제거하여 구조를 단순화하고 효율성을 높이는 데 중점을 둡니다. 제1 정규형을 이해하기 위해 그 정의와 적용 방법, 그리고 이를 통해 얻을 수 있는 이점을 자세히 알아보겠습니다.
제1 정규형의 정의
제1 정규형은 다음 두 가지 주요 조건을 충족해야 합니다:
-
원자값(Atomic Value): 테이블의 각 컬럼(속성)은 더 이상 나눌 수 없는 원자적 값을 가져야 합니다. 즉, 각 셀에는 하나의 값만 포함되어야 합니다.
-
반복 그룹 없음(No Repeating Groups): 테이블의 구조에서 반복적인 컬럼이나 데이터가 존재해서는 안 됩니다.
제1 정규형의 필요성
1NF는 데이터베이스를 정리된 형태로 유지하여 데이터를 보다 효율적으로 관리할 수 있도록 도와줍니다. 이를 통해 중복 데이터를 제거하고, 데이터 무결성을 보장하며, 데이터 변경 작업(수정, 삽입, 삭제 등)을 간소화할 수 있습니다.
DWM이 끊어서 세션이 로그오프 되었습니다 해결법 👆예시
1NF를 적용하기 전
다음은 비정규화된 데이터 테이블의 예입니다:
| 주문번호 | 고객명 | 주문상품 |
|---|---|---|
| 1 | 김철수 | 사과, 바나나 |
| 2 | 이영희 | 포도 |
| 3 | 박민수 | 딸기, 바나나, 포도 |
문제점
-
‘주문상품’ 컬럼에 여러 값이 포함되어 있습니다. 이는 데이터가 비원자적이라는 것을 의미합니다.
-
데이터 검색 및 수정이 복잡해집니다. 예를 들어, ‘바나나’를 주문한 고객을 찾으려면 문자열 검색을 수행해야 합니다.
1NF를 적용한 후
다음은 제1 정규형을 적용한 결과입니다.
| 주문번호 | 고객명 | 주문상품 |
| 1 | 김철수 | 사과 |
| 1 | 김철수 | 바나나 |
| 2 | 이영희 | 포도 |
| 3 | 박민수 | 딸기 |
| 3 | 박민수 | 바나나 |
| 3 | 박민수 | 포도 |
개선점
-
모든 컬럼이 원자값을 가집니다. 각 셀에는 하나의 데이터만 포함되어 있습니다.
-
데이터 검색 및 수정이 간단해졌습니다. 예를 들어, ‘바나나’를 주문한 고객을 쉽게 조회할 수 있습니다.
1NF 적용 과정
-
비원자적 컬럼 식별: 테이블에서 여러 값을 포함한 컬럼을 찾습니다. 예를 들어, 위 테이블의 ‘주문상품’ 컬럼이 비원자적입니다.
-
비원자적 데이터를 행으로 분리: 각 값을 개별 행으로 나누어 원자값만 포함하도록 만듭니다. 이는 데이터의 중복을 허용하더라도 데이터를 정리된 형태로 유지하는 데 중요합니다.
-
중복 제거: 필요하다면, 나눠진 데이터에서 불필요한 중복을 제거하여 데이터베이스 크기를 최소화할 수 있습니다.
1NF 적용의 장점과 단점
장점
-
데이터 검색 및 관리 용이: 데이터를 단일 값으로 분리하면 쿼리 실행이 더 간단하고 직관적입니다.
-
데이터 무결성 유지: 중복 데이터가 줄어들고, 데이터의 일관성이 향상됩니다.
-
확장성: 새로운 데이터를 추가하거나 기존 데이터를 변경할 때 구조적 제약이 감소합니다.
단점
-
데이터 중복 증가: 비원자적 데이터를 행으로 나누는 과정에서 중복 행이 생길 수 있습니다.
-
테이블 크기 증가: 나눠진 데이터로 인해 테이블의 행 수가 증가하여 데이터베이스 크기가 커질 수 있습니다.
결론
제1 정규형은 데이터베이스 정규화의 기초 단계로, 데이터를 정리하고 관리하기 쉽게 만드는 데 필수적입니다. 이를 통해 데이터 중복 문제와 비일관성을 줄일 수 있지만, 데이터베이스 성능 및 크기와 관련된 문제를 고려해야 합니다. 실무에서는 제1 정규형을 적용한 후, 데이터베이스의 목적에 맞는 추가 정규화를 진행하여 최적의 성능과 구조를 유지합니다.
vCPU 리소스 장애 예방 마이그레이션 👆
[…] 1NF(제1정규형): 모든 속성이 원자값을 가지도록 데이터 구조를 변환합니다. […]